Global poverty remains a significant challenge, with up to 29% of global aid failing to achieve its intended outcomes due to issues like bribery, theft, and embezzlement, costing $500 billion annually in health expenditure. To address these inefficiencies, Simprints is partnering with governments, NGOs, and donors to provide biometric solutions for improved program monitoring, beneficiary identification, and coverage verification.
This project focused on developing a pipeline for data scientists to test fingerprint software development kits (SDKs) using large biometric datasets. Simprints aimed to select the SDK that best aligned with their needs and future goals.
The primary task was to develop a pipeline for testing fingerprint SDKs. This involved breaking the work into sub-tasks, such as building bash scripts for individual functions, testing each component with synthetic data on a local machine, and eventually deploying the solution in a Docker container for cloud-based execution. Each sub-task was thoroughly tested to ensure it worked effectively within the larger pipeline.
The key outcome was the development of a pipeline that data scientists can use to test their fingerprint SDK.
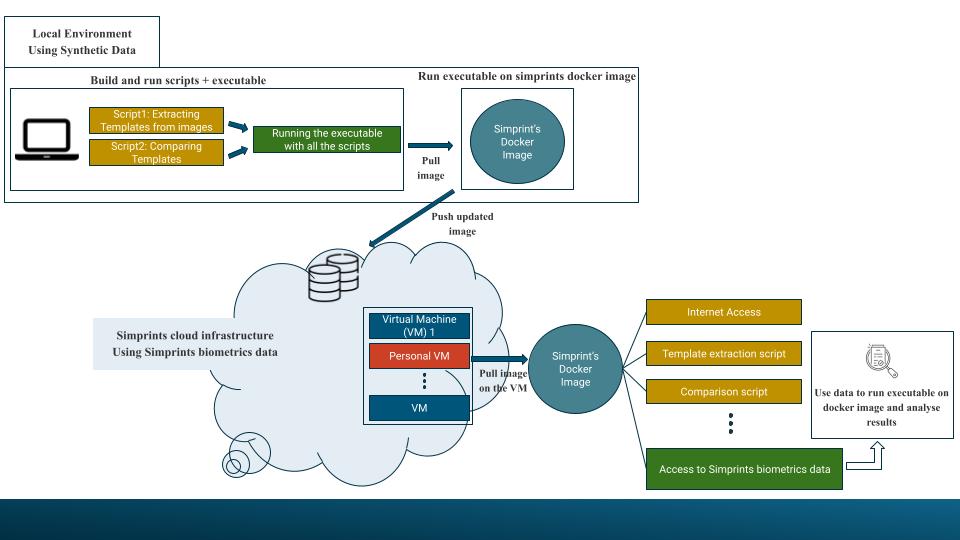
Project Workflow / Deogratias Amani